Qualitative - Methods for Data Collection
Week 5 + 6 - Qualitative Data Collection and Analysis: One of the major paradigms in LIS research is the collection and analysis of data using qualitative methods. In this two week class session we will discuss data collection methods like interviews, surveys, and content analysis. We will also discuss analytic techniques such as interview coding, memo writing, and ethnographic reporting.
Introduction
Over the next four weeks, we will be discussing the collection and analysis of data through different research methodologies. The methodologies of LIS can be, broadly, divided into qualitative and quantitative.
If you remember back in Week 1, the conceptual foundations of research, we discussed two broad paradigms of LIS: Positivism and Constructivism.
We said that these two paradigms - made up of beliefs about how we know what we know (epistemology), and what reality consists of (ontology) - can often (though not always) correspond with quantitative and the qualitative methodologies. Positivists tend to prefer quantitative methods because they enable the direct measurement and reporting of results that can be right or wrong - that is they have a measurable truth value. Constructivists, oppositely, prefer qualitative methods that allow for the explanation and interpretation of data through multiple points of view. In doing so, the constructivist does not believe that there is any one ‘right’ or ‘wrong’ answer, but that there are multiple truths that can be equally supported by rigorous and carefully executed research.
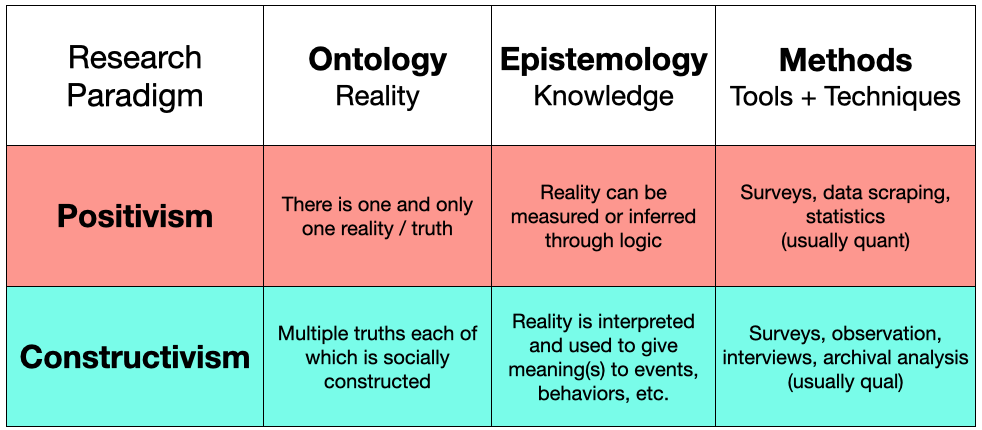
In articulating research questions to ask and answer - we have likely leaned strongly towards one paradigm or another. That is, in simply putting words to the topics that we want to research we are likely to be assuming that there are right / wrong answers, knowable truths, etc. This is because our research questions build upon sound reasoning. We argue that something is important based on relevance to peoples lives, to a gap in the literature, to public policy, etc. When we build these ‘logically’ sound arguments we tip our hand as to whether we are going to use a qualitative method as a constructivist, or a quantitive method as a positivist.
Once we begin to operationalize our research (that is, put our research questions into practice) then we start to follow a reasoning or logic that corresponds with our methodology. (Note: This can get a little confusing with all of the divisions and bins we find ourselves sorted into - but let me offer a few definitions that can help us make sense of what kind of methods, paradigms, and reasoning we’re engaged in when we execute a research project.)
When we engage in research that tests a theory, or attempts to build upon existing knowledge by conducting a study with a new population we are often working deductively - we are moving from the general to the specific.
Oppositely, when we start by making observations about the world not informed by an existing theory (explanation) then we are engaged in an ‘inductive’ logic - we develop hypotheses (or explanations) based on the patterns that we infer from our observations. When we reach a certainty about, or have our hypothesis confirmed repeatedly we then develop a theory that explains how or why some aspect of the social world operates the way that it does.
Another simple way to think about this is that when we produce theories - we start with observations (data) and explain repeated examples or patterns as evidence for our theories (explanations). This is inductive reasoning or logic. When we test theories we are informed about how the world should work and we then state clearly our expectations, make observations, and then confirm or deny whether or not our expectations have been met based on the the patterns of our observations.
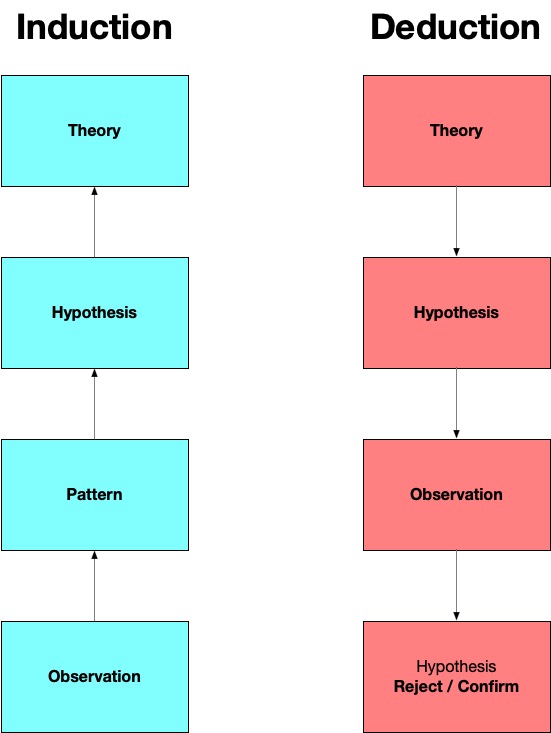
Often, but not always, a qualitative research project will use inductive reasoning and a quantitative research project will use deductive reasoning. This makes sense if we step back and think about the way that quantitative and qualitative research is designed: Qualitative researchers are making sense of the world by advancing an argument based on their own development of patterns that they see and interpret data; and, Quantitative researchers are making sense of the world by attempting to confirm or reject a hypothesis - something that should be true if a theory is correct.
The reasoning or logic behind how we design our research has some obvious implications for the methods that we choose to operationalize that research - If we want to test a hypothesis about an existing theory, then we probably need to use a method that allows us to closely control for the different variables that may fluctuate or change during our test. These methods might include a survey, an experiment, or the reuse of some existing data that we obtain from a previous study like the USA Census. If, on the other hand, we want to advance an argument about something new, or something relatively unexplored then we are likely going to use a method that allows us to gather some data, make sense of it through our own interpretations, and then offer some explanations based on our construction of a truth. These interpretive methods might include a diary study where we ask participants to write down the experience, an interview where we construct meaning with our participants through question and answers, or even an observational study where we record memos about a set of meaningful events that act as evidence for our interpretations.
The point here is that we select research research methods that match our paradigm’s commitments to truth - these ideas of truth compliment each other through logic, and practical steps in data collection and analysis.
Collecting Data using Qualitative Methods
This week, we are going to talk all about the concept of collecting data using qualitative methods. As such, we are going to focus our attention first on collecting observations, and then think, secondly about how we go about making sense of and arranging these data to answer our research questions through analysis. In the context of the four research stages that we discussed last week [^1], we are moving from Design to Execution. But, remember that we have two important concepts of research design that are method dependent, and so we need to pull those forward as begin data collection: 1. The instrument that will guide our research data collection; and, 2. a plan to manage our collected data responsibly.
We will review three particular methods of data collection in the qualitative tradition - but please note that there are many other methods that exist for both collecting and analyzing data inductively. The three methods we will focus on are the structured and semi-structured interview, the process of conducting a content analysis, and participant observation. For each method we’ll first discuss the goal, and value to using this approach. We will then describe relevant sampling methods, what data are produced, and how we should consider the sensitivities of these data as we manage a research project over the long-term.
Interviews
The logic of using an interview to collect data is similar in appearance, but ultimately quite different than a policing or journalistic sense of the informant interview where a “source” reveals key facts about an event. Remember that a researcher working under a constructivist paradigm sees the world as socially constructed. If this is the case, then understanding how and through what means of negotiation reality is constructed turns out to be paramount of importance to the constructivist. Interviews - that is talking with someone in a structured way of question and answering - helps a research understand the ways that individuals make sense of the world, experience reality, or interpret the meaning of an event. The critical thing to keep in mind is that the interviewer isn’t simply a vessel to be filled with the knowledge of an interviewee - a research interviewer helps an interviewee construct and give words to their experiences through a back and forth that is more conversational than it is an interrogation. The qualitative interview is as much about recording someones experience than it is fact-finding mission.
-
Value: A deep record of the lived experience and interpretation of key members of a community, culture, or place.
-
Sampling: The logic of sampling in qualitative interviews depends strongly upon the unit of analysis and observation. After a unit of observation is clearly identified, then a sample of representativeness can be developed. Typically we can think about the size of an interview sample consisting of anywhere from 10 to 100 participants. The size of the sample depends, again, on the concept being studied as well as the time, budget, and experience of the interviewer
-
Instrument: In advance of an interview a researcher typically develops a questionnaire that consists of open-ended questions that will be asked of all participants. For the sake of internal validity, the questions asked between interviews should remain the same. This ensures that the same topics, the same concepts, and even the same wording of questions can spark similar or different reactions from participants. Interviews can be conducted by telephone, video-conference, in-person and even text chat. Procedurally, a research interview begins with a participant giving informed consent, and then proceeds through the questions that are present in a questionnaire. It is a best practice to share the questionnaire and informed consent document with a participant before a scheduled interview. Interviews are often recorded either as a video or audio for later analysis (we will discuss this next week).
-
Data: The data produced by an interview is quite literally a record of the conversation that took place. Often times this will consist of a digital audio file that is stored for later analysis. Most researchers will also produce a transcript of the audio recording for later analysis. In total, what is stored for each participant is an interview recording, a transcript, and a signed informed consent form (if applicable).
-
Sensitivities: As we’ve discussed throughout this section, an interview is a meaning-making process by which an individual shares with a researcher the way they construct a reality or experience. When researching topics that may have implications for privacy, or require participant protections, it is necessary to construct a set of anonymous identifiers for your participants. This means that instead of referring to them by name in documentation, file names, or even in your final analysis or write up you use a pseudonym code. This can be as simple as Participant 1, 2 or 3 - and as complex as a naming scheme like Par406NE (which might be the fourth participant who participated in an interview on the sixth day of your research project and lives in the NorthEast of the USA).One important note here - even if you have a set of participants that want to be identified by name or title in your research you should resist doing so. In part, because participants are not always in a position to accurately judge the implications of their words on their privacy (or right to be let alone), and second, this can create a bias in the reporting stage of your research.
Recent notable interview studies in Information Science research:
- Fiesler, C., Morrison, S., & Bruckman, A. S. (2016, May). An archive of their own: a case study of feminist HCI and values in design. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (pp. 2574-2585). PDF
- Lutz, C., Schöttler, M., & Hoffmann, C. P. (2019). The privacy implications of social robots: Scoping review and expert interviews. Mobile Media & Communication, 7(3), 412-434. HTML (see in particular the Questionnaire that appears at the end)
- Zavala, J., Migoni, A. A., Caswell, M., Geraci, N., & Cifor, M. (2017). ‘A process where we’re all at the table’: community archives challenging dominant modes of archival practice. Archives and Manuscripts, 45(3), 202-215. PDF
Document / Content Analysis
Social scientists often look to documents - including texts, images, video, and other media forms - as a source of evidence about social phenomena. Whereas an interview or survey will allow a participant to self-report their experiences, behaviors, or preferences - document analysis allows a researcher to infer, or indirectly interpret and look for answers to their research questions through cultural artifacts. Documents, in this sense, can include texts, video, audio, or any other form of analogue or digital media. Document analysis, conceptually, is an extension of the constructivists assumptions about the social construction of reality. If, for example, an LIS researcher believes that meaning or truth is shaped by a negotiation between people and different information artifacts then it makes sense to not only study people, but also the objects that they design, use, and share. Documentary analysis takes these objects as a serious locus of study - attempting to build meaning from their contents.
Document analysis is often used in combination with, or as a compliment to another data collection method. For example, if we were interested in asking why people edit Wikipedia we could conduct interviews by recruiting people who edit Wikipedia. We might also find and analyze articles they wrote as further evidence about their motivations and behaviors on Wikipedia. This form of combining methods in qualitative research is called triangulation - by using multiple pieces of evidence the constructivist can rigorously gather data and conclusively justify their beliefs (aka - prove that they have knowledge).
Document analysis is closely related to a method of content analysis - which focuses on the internal characteristics of media, such as the presence of certain words, themes, or patterns within some given qualitative data. When either document or content analysis focuses on concepts (e.g. a theme in a document) a researcher is often looking for the frequency - that is how many times a theme is present and to what effect. For example, if we were to do a content analysis of popular newspapers about the use of the word “privacy” - we might seek to argue that privacy has become more dominant a theme in the past thirty years (and it has). Researchers conducting document or content analysis can also go a step further and look for relationships between concepts or between texts. For example, we might look at instructions for using Excel across computer labs at a university to understand how different concepts related to data entry are communicated to undergraduate students. The relational or conceptual approach to analyzing texts both draws upon the idea of first deciding on a particular theme or even word to analyze, and then looking for examples within a piece of media. The participants in document and content analysis may be objects, but ultimately they are the products of particular people and cultures. Thus, they demand our respect and careful attention, just as human subjects would.
-
Advantages While interviews and other “self reporting” methods of data collection can be valuable because the researcher has direct control over what is produced (e.g. the questions being asked) there are some very strong advantages to doing document and content analysis research. First, the method is inexpensive to perform - it requires relatively little in the way of funding to gather documents. Second, the subject (e.g. documents) are generally stable - they can be accessed at times that are convenient and amenable to a researcher. Third, content and document analysis allow the researcher to cover more topics and shift their interest in topics more easily. There are no participants to recruit and no interviews to transcribe - one simply needs to have a logic for collecting documents and method for analysis.
-
Value: The value of document and content analysis is that it provides a direct, cheap, and flexible method of data collection that can be used to triangulate and improve interpretation of a theme in one’s research. Moreover, the method is unobtrusive and requires little participant engagement. The analysis produced by content and document analysis is also easily shareable and clearly citeable within research reports.
-
Instrument: The instruments used in document and content analysis include a codebook and a corpus. A codebook formally defines what themes or words will be identified, and provides a description of how the themes or words will be compared or explained. A corpus is a set of digital objects, documents, or archived physical objects that are assembled for analysis. There needs to be clear documentation or an explanation of how these objects will be assembled, and in what ways these documents are ‘representative’ of the broader population of documents that exist. So, just like our sampling of people, we can sample documents using techniques like randomization, stratification, or clustering.
-
Data: The data produced by a document or content analysis is nothing more than the codebook, corpus, and any notes or annotations that are made to the corpus. Storing this type of data rarely requires anonymity or the creation of identifiers. Instead, software such as Zotero or Atlas.TI are used to store documents / codes. (We will discuss both approaches next week in qualitative data analysis)
-
Sensitivities: One of the strong advantages to document and content analysis is that it rarely uses or produces sensitive data that needs to protect human subjects. However, there are some cases where this is clearly a concern - such as when documents are gathered that contain personally identifiable information (PII), or when, for example, documents are shared by research participants that have already completed interviews. In these cases, just like with interview data, steps need to be taken to either remove identifying information or mask this information so that if shared it would not be harmful to a participant.
Participant Observation
The final qualitative data collection method we will explore in this course is related to the systematic collection of observational data. Similar in tradition methods used in anthropology and cultural studies, a participant observation requires a researcher to turn themselves into an instrument for data collection. More specifically, the researcher embeds themselves in a particular setting, culture, or organization in order to observe specific events and describe their broader contextual meanings.
At face value, participant observation may sound less like a research method and more like simple journalistic “reporting” - and this is a fair assumption based on our lay use of the word “observation.” But, in social science research methods what we mean by an observation is more nuanced and specific to act of interpretation. When a researcher engages in participant observation they have immersed themselves in a particular place for the act of not simply reporting, but explaining to a specific audience the multiple ways an event may be described and understood. For example, one of my favorite pieces of participant observation is Gabriella Coleman’s book “Hacker, Hoaxer, Whistleblower, Spy: The Many Faces of Anonymous”. In this research Coleman spends multiple years observing the online activity of the hacking group Anonymous. Her work interprets and explains the reasons why this group took action against certain people on the internet, how they coordinated their work, and why (contrary to popular reporting) the notion of a single authoritative organization behind Anonymous was misplaced. In short, Coleman uses herself, her theory, and her interaction with Anonymous to offer a deep explanation of how and why a group of people connected via the internet perpetuate as well as defy the stereotype of a “hacker.”
Participant observation is often, but not always, coupled with qualitative methods like interviews and documentary analysis. Like the document analyst, when a participant observer collects evidence using different methods they are working towards a more rigorous justification of their beliefs (or what we called ‘triangulation’).
- Value: Participant observation produces rich narratives about the lived world of participants based on the interpretation of a researcher. These observations are free from participant bias, occur in natural and therefore comfortable environments, and often times compliment other modes of qualitative data collection.
- Sampling: Unlike interviews or document analysis as standalone methods, participant observation is rarely focused on units of analysis that include people - but instead what are called “sites” of observation. For example, a branch library, a computer lab, or even a street corner may all be “sites” where this kind of research is conducted. Choosing sites for observation depends on a justification about why the site is meaningful and for how long the observation will be conducted (both in terms of frequency of observation and duration of observation).
- Instrument: In participant observation, the researcher is often their own interpretive instrument. This means that the thoughts and observations made by the researcher are, in many ways, the data that are collected. However, this does not mean that any subjective view is within scope of an observation for analysis. In advance of the first planned observation a researcher will record assumptions that they have about the site’s relevance, the expected occurrences or activities, and what actors or participants are deemed important to interpreting these activities. Over time the researcher will return to these records in order to update and record how their assumptions either matched or deviated from the actual observations that were recorded. This process of going back and forth from assumptions, to observations, to documentation is called “reflexivity” and it is the key activity of observation-based analysis in the social sciences.
- Data: The data produced by observation are the records of assumptions and justification for research (described above) as well as the systematic recording of a field or site note and memo. During each observation period a researcher will record notes about what they are observing, attempting to not necessarily explain the relevance, but mostly just documenting what is happening. These notes act as the basis for a summative memo that is written after each observation is complete. The memo will take the step of trying to explain what was observed, and how those observations may be relevant to answering the broader research questions that are being asked in the study.
- Sensitivities: Participant observation can produce highly sensitive data as it depends upon capturing events, activities, and the interactions of people in particular places at particular times. Reliably protecting the identity of those participants, like in an interview method, is a responsibility of the researcher to manage. This management of participant identifiable data requires using anonymous identifiers, and the safe storage of data (e.g. notes and memos) in locations that are stable and secure.
Readings
Smith, M., & Bowers-Brown, T. (2010). Different kinds of qualitative data collection methods. Practical research and evaluation: A start-to-finish guide for practitioners, 111-125. PDF
LIS Research Spotlight
Loudon, K., Buchanan, S., & Ruthven, I. (2016). The everyday life information seeking behaviours of first-time mothers. Journal of Documentation. PDF
Lopatovska, I., Rink, K., Knight, I., Raines, K., Cosenza, K., Williams, H., … & Martinez, A. (2019). Talk to me: Exploring user interactions with the Amazon Alexa. Journal of Librarianship and Information Science, 51(4), 984-997. PDF
Suggested
Costello, L., McDermott, M.-L., & Wallace, R. (2017). Netnography: Range of Practices, Misperceptions, and Missed Opportunities. International Journal of Qualitative Methods, 16(1), 1609406917700647. Link
Nowell, L. S., Norris, J. M., White, D. E., & Moules, N. J. (2017). Thematic Analysis: Striving to Meet the Trustworthiness Criteria. International Journal of Qualitative Methods, 16(1), 1609406917733847. Link
Charmaz, K., & Belgrave, L. L. (2019). Thinking About Data With Grounded Theory. Qualitative Inquiry, 25(8), 743–753. Link
Paulus, T. M., Jackson, K., & Davidson, J. (2017). Digital Tools for Qualitative Research: Disruptions and Entanglements. Qualitative Inquiry, 23(10), 751–756. Link
Exercise
Forthcoming